C++ Functions
Related Documentation Pages
On This Page
Using functions we can structure our programs in a more modular way, accessing all the potential that structured programming can offer to us in C++.
A function is a group of statements that is executed when it is called from some point of the program. The following is its format:
type name ( parameter1, parameter2, ...) { statements }
where:
- type is the data type specifier of the data returned by the function.
- name is the identifier by which it will be possible to call the function.
- parameters (as many as needed): Each parameter consists of a data type specifier followed by an identifier, like any regular variable declaration (for example: int x) and which acts within the function as a regular local variable. They allow to pass arguments to the function when it is called. The different parameters are separated by commas.
- statements is the function's body. It is a block of statements surrounded by braces { }.
Here you have the first function example:
// function example #include <iostream> using namespace std; int addition (int a, int b) { int r; r=a+b; return (r); } int main () { int z; z = addition (5,3); cout << "The result is " << z; return 0; } /* Output The result is 8 */
In order to examine this code, first of all remember something said at the beginning of this tutorial: a C++ program always begins its execution by the main function. So we will begin there.
We can see how the main function begins by declaring the variable z of type int. Right after that, we see a call to a function called addition. Paying attention we will be able to see the similarity between the structure of the call to the function and the declaration of the function itself some code lines above:

The parameters and arguments have a clear correspondence. Within the main function we called to addition passing two values: 5 and 3, that correspond to the int a and int b parameters declared for function addition.
At the point at which the function is called from within main, the control is lost by main and passed to function addition. The value of both arguments passed in the call (5 and 3) are copied to the local variables int a and int b within the function.
Function addition declares another local variable (int r), and by means of the expression r=a+b, it assigns to r the result of a plus b. Because the actual parameters passed for a and b are 5 and 3 respectively, the result is 8.
The following line of code:
return (r);
finalizes function addition, and returns the control back to the function that called it in the first place (in this case, main). At this moment the program follows its regular course from the same point at which it was interrupted by the call to addition. But additionally, because the return statement in function addition specified a value: the content of variable r (return (r);), which at that moment had a value of 8. This value becomes the value of evaluating the function call.
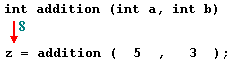
So being the value returned by a function the value given to the function call itself when it is evaluated, the variable z will be set to the value returned by addition (5, 3), that is 8. To explain it another way, you can imagine that the call to a function (addition (5,3)) is literally replaced by the value it returns (8).
The following line of code in main is:
cout << "The result is " << z;
That, as you may already expect, produces the printing of the result on the screen.
Scope of Variables
The scope of variables declared within a function or any other inner block is only their own function or their own block and cannot be used outside of them. For example, in the previous example it would have been impossible to use the variables a, b or r directly in function main since they were variables local to function addition. Also, it would have been impossible to use the variable z directly within function addition, since this was a variable local to the function main.
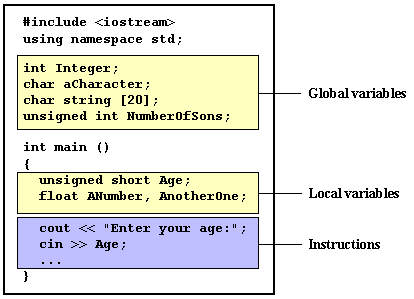
Therefore, the scope of local variables is limited to the same block level in which they are declared. Nevertheless, we also have the possibility to declare global variables; These are visible from any point of the code, inside and outside all functions. In order to declare global variables you simply have to declare the variable outside any function or block; that means, directly in the body of the program.
And here is another example about functions:
// function example #include <iostream> using namespace std; int subtraction (int a, int b) { int r; r=a-b; return (r); } int main () { int x=5, y=3, z; z = subtraction (7,2); cout << "The first result is " << z << '\n'; cout << "The second result is " << subtraction (7,2) << '\n'; cout << "The third result is " << subtraction (x,y) << '\n'; z= 4 + subtraction (x,y); cout << "The fourth result is " << z << '\n'; return 0; } /* Output The first result is 5 The second result is 5 The third result is 2 The fourth result is 6 */
In this case we have created a function called subtraction. The only thing that this function does is to subtract both passed parameters and to return the result.
Nevertheless, if we examine function main we will see that we have made several calls to function subtraction. We have used some different calling methods so that you see other ways or moments when a function can be called.
In order to fully understand these examples you must consider once again that a call to a function could be replaced by the value that the function call itself is going to return. For example, the first case (that you should already know because it is the same pattern that we have used in previous examples):
z = subtraction (7,2); cout << "The first result is " << z;
If we replace the function call by the value it returns (i.e., 5), we would have:
z = 5; cout << "The first result is " << z;
As well as:
cout << "The second result is " << subtraction (7,2);
has the same result as the previous call, but in this case we made the call to subtraction directly as an insertion parameter for cout. Simply consider that the result is the same as if we had written:
cout << "The second result is " << 5;
since 5 is the value returned by subtraction (7,2).
In the case of:
cout << "The third result is " << subtraction (x,y);
The only new thing that we introduced is that the parameters of subtraction are variables instead of constants. That is perfectly valid. In this case the values passed to function subtraction are the values of x and y, that are 5 and 3 respectively, giving 2 as result.
The fourth case is more of the same. Simply note that instead of:
z = 4 + subtraction (x,y);
we could have written:
z = subtraction (x,y) + 4;
with exactly the same result. I have switched places so you can see that the semicolon sign (;) goes at the end of the whole statement. It does not necessarily have to go right after the function call. The explanation might be once again that you imagine that a function can be replaced by its returned value:
z = 4 + 2; z = 2 + 4;
Functions with no type (Void)
If you remember the syntax of a function declaration:
type name ( argument1, argument2 ...) statement
you will see that the declaration begins with a type, that is the type of the function itself (i.e., the type of the datum that will be returned by the function with the return statement). But what if we want to return no value?
Imagine that we want to make a function just to show a message on the screen. We do not need it to return any value. In this case we should use the void type specifier for the function. This is a special specifier that indicates absence of type.
// void function example #include <iostream> using namespace std; void printmessage () { cout << "I'm a function!"; } int main () { printmessage (); return 0; } /* Output I'm a function! */
void can also be used in the function's parameter list to explicitly specify that we want the function to take no actual parameters when it is called. For example, function printmessage could have been declared as:
void printmessage (void) { cout << "I'm a function!"; }
Although it is optional to specify void in the parameter list. In C++, a parameter list can simply be left blank if we want a function with no parameters.
What you must always remember is that the format for calling a function includes specifying its name and enclosing its parameters between parentheses. The non-existence of parameters does not exempt us from the obligation to write the parentheses. For that reason the call to printmessage is:
printmessage();
The parentheses clearly indicate that this is a call to a function and not the name of a variable or some other C++ statement. The following call would have been incorrect:
printmessage;
Arguments passed by value and by reference
Until now, in all the functions we have seen, the arguments passed to the functions have been passed by value. This means that when calling a function with parameters, what we have passed to the function were copies of their values but never the variables themselves. For example, suppose that we called our first function addition using the following code:
int x=5, y=3, z; z = addition ( x , y );
What we did in this case was to call to function addition passing the values of x and y, i.e. 5 and 3 respectively, but not the variables x and y themselves.
This way, when the function addition is called, the value of its local variables a and b become 5 and 3 respectively, but any modification to either a or b within the function addition will not have any effect in the values of x and y outside it, because variables x and y were not themselves passed to the function, but only copies of their values at the moment the function was called.
But there might be some cases where you need to manipulate from inside a function the value of an external variable. For that purpose we can use arguments passed by reference, as in the function duplicate of the following example:
// passing parameters by reference #include <iostream> using namespace std; void duplicate (int& a, int& b, int& c) { a*=2; b*=2; c*=2; } int main () { int x=1, y=3, z=7; duplicate (x, y, z); cout << "x=" << x << ", y=" << y << ", z=" << z; return 0; } /* Output x=2, y=6, z=14 */
The first thing that should call your attention is that in the declaration of duplicate the type of each parameter was followed by an ampersand sign (&). This ampersand is what specifies that their corresponding arguments are to be passed by reference instead of by value.
When a variable is passed by reference we are not passing a copy of its value, but we are somehow passing the variable itself to the function and any modification that we do to the local variables will have an effect in their counterpart variables passed as arguments in the call to the function.
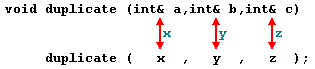
To explain it in another way, we associate a, b and c with the arguments passed on the function call (x, y and z) and any change that we do on a within the function will affect the value of x outside it. Any change that we do on b will affect y, and the same with c and z.
That is why our program's output, that shows the values stored in x, y and z after the call to duplicate, shows the values of all the three variables of main doubled.
If when declaring the following function:
void duplicate (int& a, int& b, int& c)
we had declared it this way:
void duplicate (int a, int b, int c)
i.e., without the ampersand signs (&), we would have not passed the variables by reference, but a copy of their values instead, and therefore, the output on screen of our program would have been the values of x, y and z without having been modified.
Passing by reference is also an effective way to allow a function to return more than one value. For example, here is a function that returns the previous and next numbers of the first parameter passed.
// more than one returning value #include <iostream> using namespace std; void prevnext (int x, int& prev, int& next) { prev = x-1; next = x+1; } int main () { int x=100, y, z; prevnext (x, y, z); cout << "Previous=" << y << ", Next=" << z; return 0; } /* Output Previous=99, Next=101 */
Default Values in Parameters
When declaring a function we can specify a default value for each of the last parameters. This value will be used if the corresponding argument is left blank when calling to the function. To do that, we simply have to use the assignment operator and a value for the arguments in the function declaration. If a value for that parameter is not passed when the function is called, the default value is used, but if a value is specified this default value is ignored and the passed value is used instead. For example:
// default values in functions #include <iostream> using namespace std; int divide (int a, int b=2) { int r; r=a/b; return (r); } int main () { cout << divide (12); cout << endl; cout << divide (20,4); return 0; } /* Output 6 5 */
As we can see in the body of the program there are two calls to function divide. In the first one:
divide (12)
we have only specified one argument, but the function divide allows up to two. So the function divide has assumed that the second parameter is 2 since that is what we have specified to happen if this parameter was not passed (notice the function declaration, which finishes with int b=2, not just int b). Therefore the result of this function call is 6 (12/2).
In the second call:
divide (20,4)
there are two parameters, so the default value for b (int b=2) is ignored and b takes the value passed as argument, that is 4, making the result returned equal to 5 (20/4).
Overloaded Functions
In C++ two different functions can have the same name if their parameter types or number are different. That means that you can give the same name to more than one function if they have either a different number of parameters or different types in their parameters. For example:
// overloaded function #include <iostream> using namespace std; int operate (int a, int b) { return (a*b); } float operate (float a, float b) { return (a/b); } int main () { int x=5,y=2; float n=5.0,m=2.0; cout << operate (x,y); cout << "\n"; cout << operate (n,m); cout << "\n"; return 0; } /* Output 10 2.5 */
In this case we have defined two functions with the same name, operate, but one of them accepts two parameters of type int and the other one accepts them of type float. The compiler knows which one to call in each case by examining the types passed as arguments when the function is called. If it is called with two ints as its arguments it calls to the function that has two int parameters in its prototype and if it is called with two floats it will call to the one which has two float parameters in its prototype.
In the first call to operate the two arguments passed are of type int, therefore, the function with the first prototype is called; This function returns the result of multiplying both parameters. While the second call passes two arguments of type float, so the function with the second prototype is called. This one has a different behavior: it divides one parameter by the other. So the behavior of a call to operate depends on the type of the arguments passed because the function has been overloaded.
Notice that a function cannot be overloaded only by its return type. At least one of its parameters must have a different type.
Inline Functions
The inline specifier indicates the compiler that inline substitution is preferred to the usual function call mechanism for a specific function. This does not change the behavior of a function itself, but is used to suggest to the compiler that the code generated by the function body is inserted at each point the function is called, instead of being inserted only once and perform a regular call to it, which generally involves some additional overhead in running time.
The format for its declaration is:
inline type name ( arguments ... ) { instructions ... }
and the call is just like the call to any other function. You do not have to include the inline keyword when calling the function, only in its declaration.
Most compilers already optimize code to generate inline functions when it is more convenient. This specifier only indicates the compiler that inline is preferred for this function.
Recursivity
Recursivity is the property that functions have to be called by themselves. It is useful for many tasks, like sorting or calculate the factorial of numbers. For example, to obtain the factorial of a number (n!) the mathematical formula would be:
n! = n * (n-1) * (n-2) * (n-3) ... * 1
more concretely, 5! (factorial of 5) would be:
5! = 5 * 4 * 3 * 2 * 1 = 120
and a recursive function to calculate this in C++ could be:
// factorial calculator #include <iostream> using namespace std; long factorial (long a) { if (a > 1) return (a * factorial (a-1)); else return (1); } int main () { long number; cout << "Please type a number: "; cin >> number; cout << number << "! = " << factorial (number); return 0; } /* Output Please type a number: 9 9! = 362880 */
Notice how in function factorial we included a call to itself, but only if the argument passed was greater than 1, since otherwise the function would perform an infinite recursive loop in which once it arrived to 0 it would continue multiplying by all the negative numbers (probably provoking a stack overflow error on runtime).
This function has a limitation because of the data type we used in its design (long) for more simplicity. The results given will not be valid for values much greater than 10! or 15!, depending on the system you compile it.
Declaring Functions
Until now, we have defined all of the functions before the first appearance of calls to them in the source code. These calls were generally in function main which we have always left at the end of the source code. If you try to repeat some of the examples of functions described so far, but placing the function main before any of the other functions that were called from within it, you will most likely obtain compiling errors. The reason is that to be able to call a function it must have been declared in some earlier point of the code, like we have done in all our examples.
But there is an alternative way to avoid writing the whole code of a function before it can be used in main or in some other function. This can be achieved by declaring just a prototype of the function before it is used, instead of the entire definition. This declaration is shorter than the entire definition, but significant enough for the compiler to determine its return type and the types of its parameters.
Its form is:
type name ( argument_type1, argument_type2, ...);
It is identical to a function definition, except that it does not include the body of the function itself (i.e., the function statements that in normal definitions are enclosed in braces { }) and instead of that we end the prototype declaration with a mandatory semicolon (;).
The parameter enumeration does not need to include the identifiers, but only the type specifiers. The inclusion of a name for each parameter as in the function definition is optional in the prototype declaration. For example, we can declare a function called protofunction with two int parameters with any of the following declarations:
int protofunction (int first, int second); int protofunction (int, int);
Anyway, including a name for each variable makes the prototype more legible.
// declaring functions prototypes #include <iostream> using namespace std; void odd (int a); void even (int a); int main () { int i; do { cout << "Type a number (0 to exit): "; cin >> i; odd (i); } while (i!=0); return 0; } void odd (int a) { if ((a%2)!=0) cout << "Number is odd.\n"; else even (a); } void even (int a) { if ((a%2)==0) cout << "Number is even.\n"; else odd (a); } /* Output Type a number (0 to exit): 9 Number is odd. Type a number (0 to exit): 6 Number is even. Type a number (0 to exit): 1030 Number is even. Type a number (0 to exit): 0 Number is even. */
This example is indeed not an example of efficiency. I am sure that at this point you can already make a program with the same result, but using only half of the code lines that have been used in this example. Anyway this example illustrates how prototyping works. Moreover, in this concrete example the prototyping of at least one of the two functions is necessary in order to compile the code without errors.
The first things that we see are the declaration of functions odd and even:
void odd (int a); void even (int a);
This allows these functions to be used before they are defined, for example, in main, which now is located where some people find it to be a more logical place for the start of a program: the beginning of the source code.
Anyway, the reason why this program needs at least one of the functions to be declared before it is defined is because in odd there is a call to even and in even there is a call to odd. If none of the two functions had been previously declared, a compilation error would happen, since either odd would not be visible from even (because it has still not been declared), or even would not be visible from odd (for the same reason).
Having the prototype of all functions together in the same place within the source code is found practical by some programmers, and this can be easily achieved by declaring all functions prototypes at the beginning of a program.
*Last modified Monday, 07th January, 2019.